KI und Musik
Youssef Own
Auf dieser Projektseite finden Sie eine kleine Step by Step-Anleitung zum Erstellen und Trainieren Ihrer eigenen KI, um beliebige Stimmen zu klonen. Daraufhin stelle ich mein eigenes Musikprojekt vor und behandle zum Schluss auch die fragwürdigen Ethikaspekte, welche damit einhergehen.
Step by Step-Anleitung
Step 1
Als erstes beginnen Sie mit der Datenauswahl. Dafür benötigen Sie von Ihrer Zielperson ausreichendes Audiomaterial, welches die Stimme isoliert darstellt. Zum Beispiel ist es bei Musikern gut, die Stimme aus Interviewabschnitten oder Vocals von Songs zu entnehmen. Für das KI-Training sollten Sie mindestens 16-minütiges Audiomaterial exportiert als .wav-Datei sammeln. Je mehr Audiomaterial man der KI jedoch bereitstellt, desto besser kann diese trainiert werden.
Step 2
Mithilfe eines beliebigen externem Programm muss das Audiomaterial zur Datenvorbereitung in 10-Sekunden Audios gesplittet werden Diese Dateien können Sie dann in Ihrem Google Drive Ordner hochladen.
Step3
Kommen wir nun zu der eigentlichen Künstlichen Intelligenz. Dafür geben Sie in GitHub in der Suche so-vits-svc-fork ein und scrollen runter bis zum Feld Cloud und öffnen das Programm in Google Colab.

Wenn Sie das Programm in Colab geöffnet haben müssen Sie sich oben rechts über die Cloud mit der bereitgestellten Tesla T4 GPU verbinden und die GPU testen. Anschließend verknüpfen Sie Ihr Google Drive.
Step 4
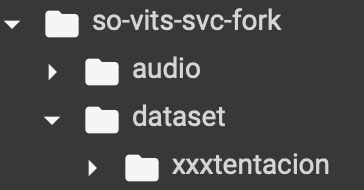
In Ihrem Google Drive erstellen Sie zunächst einen Ordner mit dem Namen „so-vits-svc-forc“ und erstellen in diesem Ordner zwei Unterordner mit den Namen „audio“ und „dataset“. Im Ordner dataset erstellen Sie einen weiteren Unterordner mit dem Namen der Zielperson. Im Unterordner mit dem Namen der Zielperson (hier „xxxtentacion“) legen Sie die zuvor erstellten 10-Sekunden-Audiodateien ab.
Step 5
Um die KI auszuführen, müssen Sie nun in Colab alle angegebenen Schritte einmal ausführen, bis Sie zum Abschnitt „Train“ gelangen.
An dem Abschnitt „Copy your dataset“ müssen sie in dem Feld rechts daneben (s. Bild) den Namen des Unterordners eingeben, in dem die Audiodateien abgespeichert wurden.

Des Weiteren sollten Sie unter der „F0_Method“ crepe einstellen, um bessere Ergebnisse der KI zu erlangen.

Step 6
Nun können Sie das Training Ihrer eigenen KI beginnen, indem sie den Abschnitt „Train“ ausführen.
Die KI wird nun mithilfe der bereitgestellten Audiodateien trainiert und speichert je nach Vorkonfiguration alle X-Durchläufe das aktuelle Trainingsmodel im Google Drive ab.
Step 7
In diesem Projekt zeige ich wie man ein Cover von einem bereits vorhandenen Song von der KI- geklonten Stimme singen lässt.
Daher erfolgt in diesem Schritt das Herunterladen eines beliebigen Originalsongs. Mithilfe eines Vocalremovers können Sie dann die jeweiligen Tonspuren von Musik und Gesang voneinander trennen
und beide als .wav-Datei herunterladen. Die Gesang-Tonspur müssen Sie dann in dem Unterordner Audio hochladen.
Step 8
Gehen Sie jetzt in das Feld „Use trainded model“ und geben dort den Dateinamen der zuvor heruntergeladenen Gesang-Tonspur ein. Nun können Sie das Ausführen beginnen und bei Abschluss wir Ihnen das fertige Gesang-Cover ebenfalls als .wav-Datei in dem „audio“-Ordner im Google Drive hochgeladen.
Step 9
Um die finale Songversion zu erhalten, müssen Sie nur noch in einem Audioprogramm die neue Gesang-Tonspur mit der Musik-Tonspur des Originalsong wieder passend übereinanderlegen.
Projekt »Christmas-Song«
Passend zur Jahreszeit habe ich mich dazu entscheiden, den Originalsong „All i want for Christmas is You“ von Mariah Carey mit der Stimme des am 18. Juni 2018 verstorbenen US-Rapper xxxtentacion zu covern.
Warum ich mich für diesen Künstler entscheiden habe, liegt an der hohen Bekanntheit des Künstlers (> 37 Mio. monatliche Zuhörer auf Spotify), der in Bezug auf die Ethikfragen einen größeren
Zwiespalt darstellt, da hier die Stimme eines verstorbenen Künstlers geklont wird.
Wie in der Step by Step Anleitung beschrieben, habe ich alle Schritte ausgeführt und am Ende ein recht akzeptables, aber leider nicht perfektes Ergebnis erhalten. Die Qualität der Ergebnisse
hätte man mit mehr Audios als Datengrundlage und insbesondere durch längeres Training der KI erreichen können.
Die KI habe ich mit insgesamt 151 10-Sekunden-Audiodateien pro Ablauf trainiert. Das Training habe ich dann bei 1619 von 9999 möglichen Abläufen beendet, wobei ein Ablauf ca. 24 Sekunden
benötigt. Dies entspricht in der Summe eine Gesamttrainingszeit von ca. 11 Stunden.
Audio-Datei
Ethikaspekte
Im Laufe des Projektes bin ich auf einige ethische Fragen gestoßen. Ich fokussiere mich hier mehr auf die folgenden ethischen Fragen:
- Sollte man Stimmen von (verstorbenen) Künstlern klonen dürfen?
- Sollte man Musik von Musikern veröffentlichen dürfen, welche nicht vom Musiker direkt stammen?
Ich habe mir viele Gedanken darüber gemacht und eine mögliche Lösung entwickelt, welche meiner Meinung nach die oben genannten Fragen gut beantwortet und die Umsetzung regulieren könnte.
Zunächst ist es gerade bei verstorbenen Künstlern besonders kritisch die Stimme zu klonen, da nicht einmal die Möglichkeit bestünde, den Musiker nach seinem Einverständnis zu fragen.
Dennoch ist es besonders für die Community des Künstlers eine positive Bereicherung, wenn man neue Musik von diesem hört – auch, wenn diese eigentlich von einer KI stammt.
Wenn es wirklich nur um das Hören von neuer Musik eines verstorbenen Künstlers geht, habe ich eine Lösung hierfür entwickelt, welche die ethischen Konflikte etwas beruhigen könnte:
Dafür ist eine Plattform erforderlich, welche stetig von Admins reguliert und kontrolliert wird. Auf dieser Plattform kann eben solche KI-generierte Musik nach der Prüfung von den Admins
hochgeladen werden. Damit soll gewährleistet werden, dass kein Künstler durch die KI-generierte Musik entmenschlicht wird. Des Weiteren soll die Community bzw. die User dieser Plattform die Musik
bewerten können und somit entschieden werden, ob diese Musik dem Künstler auch wirklich gerecht wird. Dafür werden Mindestverhältnisse festgelegt, wobei eine Unterschreitung der
Mindestanforderung die Löschung des Songs bedeutet. Eine Nebenbedingung der Plattform ist es außerdem, dass jegliche hochgeladene Musik nicht monetarisiert werden kann.